
この記事で分かること
- 半角カナ・全角カナ・ひらがなを判定するための正規表現
- 英数字・アスキー文字の判定方法
- 半角・全角のみで構成された文字列の判別方法
この記事では、Java / Kotlin で文字列が「英数字」「半角カナ」「全角カナ」「ひらがな」「半角文字」「全角文字」のみで構成されているかを判定する方法を紹介しています。
正規表現を使って実現しているものもあれば、そうでないものもあります。
それぞれ、最もシンプルで分かりやすいと思う方法を採用しています。
正規表現で実現しているものについては、他の言語であっても利用可能だと思います。
ただし、一概に半角・全角の判定と言ってもシステムによってその定義が違うため、あなたのシステムで必要としている仕様とは必ずしも一致していない可能性があります。(この記事では一般的な例を提示しています)
また、文字種の判定ではなく、半角⇔全角の変換がしたいという方は、以下の記事も合わせて参考にして下さい。
-


-
ICU4Jライブラリでスマートに全角⇔半角カナ変換する方法 [Java]
この記事では、ICU4Jを使ってスマートに全角・半角カナ変換をする方法を紹介します。 主にレガシーなシステムとやり取りをする場合に多いですが、今でも全角カナを半角カナに変換したり、逆に半角カナを全角カ ...
続きを見る
文字列判定コード
以下にサンプルコードを示しますが、分かりにくい部分について少し補足します。
- 制御文字とは、プリンタや通信機器の制御のために使われていた表示されない特殊な文字のことです(よく不具合の原因になります)
- StringUtilsを使っているものは、org.apache.commons:commons-lang3 の依存関係の追加が必要です
アスキー文字
public static boolean isAscii(String text) {
// ASCII文字 (制御文字は含まない)
return StringUtils.isAsciiPrintable(text);
}補足
アスキーコード表は以下のサイトが見やすい。
ASCIIコード表 (k-cube.co.jp)
アスキー文字を判定するコードは他にも以下のようなものが考えられます。
制御文字の有無など微妙な違いがあるので、場合によって使い分けると良いかも知れません。
public static boolean isAscii(String text) {
// CharsetEncoder#canEncodeを使ったパターン
return Charset.forName("US-ASCII").newEncoder().canEncode(v);
// Google guava CharMatcherを使ったパターン
return CharMatcher.ascii().matchesAllOf(text));
// Google guava CharMatcherを使ったパターン(制御文字なし)
return CharMatcher.inRange(' ', '~').matchesAllOf(text));
// 正規表現を使ったパターン
return text.matches("\\A\\p{ASCII}*\\z"));
}参考:java - How to check if a String contains only ASCII? - Stack Overflow
英数字
public static boolean isAlphaNumeric(String text) {
// 英数字のみ
return StringUtils.isAlphanumeric(text);
}半角カナ
public static boolean isHankakuKana(String text) {
// 半角カタカナの正規表現
return text.matches("^[ヲ-゚]+$");
}補足
半角カナを、ヲ(U+FF66) から ゚(U+FF9F) までと定義しています。
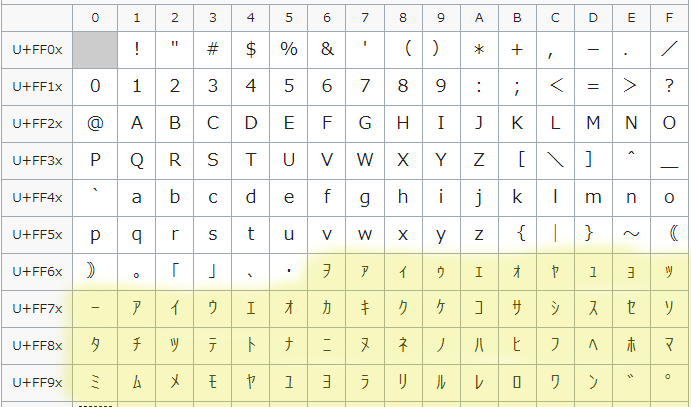
参考:https://en.wikipedia.org/wiki/Halfwidth_and_Fullwidth_Forms_(Unicode_block)
全角カナ
public static boolean isZenkakuKana(String text) {
// 全角カタカナの正規表現
return text.matches("^[ァ-ヴー]+$");
}補足
全角カナを、ァ(U+30A1) から ヴ(U+30F4) まで + 長音(U+30FC) と定義しています。
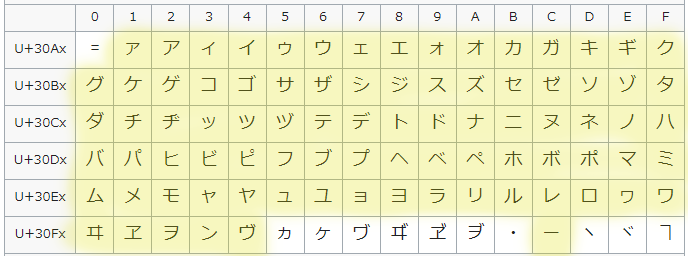
参考:https://en.wikipedia.org/wiki/Katakana_%28Unicode_block%29
ひらがな
public static boolean isHiragana(String text) {
// ひらがなの正規表現
return text.matches("^[ぁ-ん]+$");
}補足
ひらがなを、ぁ(U+3041) から ん(U+3093) までと定義しています。
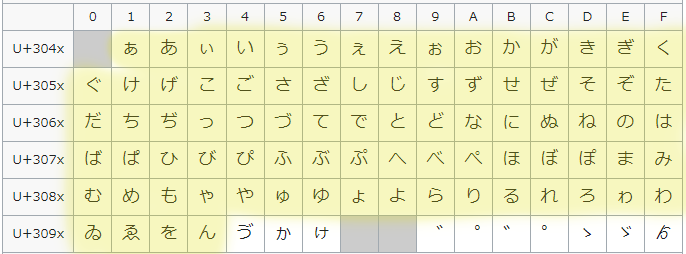
参考:https://en.wikipedia.org/wiki/Hiragana_%28Unicode_block%29
半角文字のみ
public static boolean isHankaku(String text) {
// 半角 = ASCII文字 or 半角カナ
return text.chars()
.mapToObj(Character::toString)
.allMatch((c) -> isAscii(c) || isHankakuKana(c));
}上記に記載している、アスキー文字のみ と 半角カナのみ を判定するコードを組み合わせて実現しています。
全角文字のみ
public static boolean isZenkaku(String text) {
// 全角 = (半角文字 or 制御文字) 以外
return text.chars()
.noneMatch((cp) -> isHankaku(Character.toString(cp)) || Character.isISOControl(cp));
}上記に記載している、半角文字のみ と Characterクラスの制御文字を判定するコードを組み合わせて実現しています。
テストコード
検証に使ったテストコードを示します。
それぞれの判定がどのような結果になるか分かると思います。
/**
* アスキー文字のみ
*/
@Test
public void isAsciiTest() {
assertTrue(CharValidator.isAscii("a"));
assertTrue(CharValidator.isAscii("A"));
assertTrue(CharValidator.isAscii("0"));
assertTrue(CharValidator.isAscii("!"));
assertTrue(CharValidator.isAscii(" ")); // White space
assertTrue(CharValidator.isAscii("azAZ09 !|[]/_"));
assertTrue(CharValidator.isAscii(""));
assertFalse(CharValidator.isAscii("あ"));
assertFalse(CharValidator.isAscii("ア"));
assertFalse(CharValidator.isAscii("ア"));
assertFalse(CharValidator.isAscii("漢字"));
assertFalse(CharValidator.isAscii("aあ"));
assertFalse(CharValidator.isAscii("アZ"));
assertFalse(CharValidator.isAscii("ア!"));
assertFalse(CharValidator.isAscii("0漢字9"));
assertFalse(CharValidator.isAscii("\u000F")); // SIN (Control char)
assertFalse(CharValidator.isAscii(" ")); // Full-width White space
}
/**
* 半角カナのみ
*/
@Test
public void isHankakuKanaTest() {
assertTrue(CharValidator.isHankakuKana("ア"));
assertTrue(CharValidator.isHankakuKana("ヲァィゥェォャュョッーアイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワン゙゚"));
assertFalse(CharValidator.isHankakuKana(""));
assertFalse(CharValidator.isHankakuKana("a"));
assertFalse(CharValidator.isHankakuKana("A"));
assertFalse(CharValidator.isHankakuKana("0"));
assertFalse(CharValidator.isHankakuKana("!"));
assertFalse(CharValidator.isHankakuKana(" ")); // White space
assertFalse(CharValidator.isHankakuKana("あ"));
assertFalse(CharValidator.isHankakuKana("ア"));
assertFalse(CharValidator.isHankakuKana("漢字"));
assertFalse(CharValidator.isHankakuKana("aあ"));
assertFalse(CharValidator.isHankakuKana("アZ"));
assertFalse(CharValidator.isHankakuKana("ア!"));
assertFalse(CharValidator.isHankakuKana("0漢字9"));
assertFalse(CharValidator.isHankakuKana("\u000F")); // SIN (Control char)
assertFalse(CharValidator.isHankakuKana(" ")); // Full-width White space
}
/**
* 全角カナのみ
*/
@Test
public void isZenkakuKanaTest() {
assertTrue(CharValidator.isZenkakuKana("ア"));
assertTrue(CharValidator.isZenkakuKana("ァアィイゥウェエォオカガキギクグケゲコゴサザシジスズセゼソゾ" +
"タダチヂッツヅテデトドナニヌネノハバパヒビピフブプヘベペホボポマミムメモャヤユユヨヨラリルレロヮワヰヱヲンヴー"));
assertFalse(CharValidator.isZenkakuKana(""));
assertFalse(CharValidator.isZenkakuKana("a"));
assertFalse(CharValidator.isZenkakuKana("A"));
assertFalse(CharValidator.isZenkakuKana("0"));
assertFalse(CharValidator.isZenkakuKana("!"));
assertFalse(CharValidator.isZenkakuKana(" ")); // White space
assertFalse(CharValidator.isZenkakuKana("あ"));
assertFalse(CharValidator.isZenkakuKana("ア"));
assertFalse(CharValidator.isZenkakuKana("漢字"));
assertFalse(CharValidator.isZenkakuKana("aあ"));
assertFalse(CharValidator.isZenkakuKana("アZ"));
assertFalse(CharValidator.isZenkakuKana("ア!"));
assertFalse(CharValidator.isZenkakuKana("0漢字9"));
assertFalse(CharValidator.isZenkakuKana("\u000F")); // SIN (Control char)
assertFalse(CharValidator.isZenkakuKana(" ")); // Full-width White space
}
/**
* ひらがなのみ
*/
@Test
public void isHiraganaTest() {
assertTrue(CharValidator.isHiragana("あ"));
assertTrue(CharValidator.isHiragana("ぁあぃいぅうぇえぉおかがきぎくぐけげこごさざしじすずせぜそぞ" +
"ただちぢっつづてでとどなにぬねのはばぱひびぴふぶぷへべぺほぼぽまみむめもゃやゅゆょよらりるれろゎわゐゑをん"));
assertFalse(CharValidator.isHiragana(""));
assertFalse(CharValidator.isHiragana("a"));
assertFalse(CharValidator.isHiragana("A"));
assertFalse(CharValidator.isHiragana("0"));
assertFalse(CharValidator.isHiragana("!"));
assertFalse(CharValidator.isHiragana(" ")); // White space
assertFalse(CharValidator.isHiragana("ア"));
assertFalse(CharValidator.isHiragana("ア"));
assertFalse(CharValidator.isHiragana("漢字"));
assertFalse(CharValidator.isHiragana("aあ"));
assertFalse(CharValidator.isHiragana("アZ"));
assertFalse(CharValidator.isHiragana("ア!"));
assertFalse(CharValidator.isHiragana("0漢字9"));
assertFalse(CharValidator.isHiragana("\u000F")); // SIN (Control char)
assertFalse(CharValidator.isHiragana(" ")); // Full-width White space
}
/**
* 半角文字のみ
*/
@Test
public void isHankakuTest() {
assertTrue(CharValidator.isHankaku(""));
assertTrue(CharValidator.isHankaku("a"));
assertTrue(CharValidator.isHankaku("A"));
assertTrue(CharValidator.isHankaku("0"));
assertTrue(CharValidator.isHankaku("!"));
assertTrue(CharValidator.isHankaku("ア"));
assertTrue(CharValidator.isHankaku("ア!"));
assertTrue(CharValidator.isHankaku(" ")); // White space
assertTrue(CharValidator.isHankaku("azAZ09ヲ゚ !|[]/_"));
assertFalse(CharValidator.isHankaku("あ"));
assertFalse(CharValidator.isHankaku("ア"));
assertFalse(CharValidator.isHankaku("漢字"));
assertFalse(CharValidator.isHankaku("aあ"));
assertFalse(CharValidator.isHankaku("アZ"));
assertFalse(CharValidator.isHankaku("0漢字9"));
assertFalse(CharValidator.isHankaku("\u000F")); // SIN (Control char)
assertFalse(CharValidator.isHankaku(" ")); // Full-width White space
}
/**
* 全角文字のみ
*/
@Test
public void isZenkakuTest() {
assertTrue(CharValidator.isZenkaku(""));
assertTrue(CharValidator.isZenkaku("あ"));
assertTrue(CharValidator.isZenkaku("ア"));
assertTrue(CharValidator.isZenkaku("a"));
assertTrue(CharValidator.isZenkaku("A"));
assertTrue(CharValidator.isZenkaku("9"));
assertTrue(CharValidator.isZenkaku("漢字"));
assertTrue(CharValidator.isZenkaku(" ")); // Full-width White space
assertTrue(CharValidator.isZenkaku("あアaA9漢字 _!"));
assertFalse(CharValidator.isZenkaku("a"));
assertFalse(CharValidator.isZenkaku("A"));
assertFalse(CharValidator.isZenkaku("0"));
assertFalse(CharValidator.isZenkaku("!"));
assertFalse(CharValidator.isZenkaku("ア"));
assertFalse(CharValidator.isZenkaku("ア!"));
assertFalse(CharValidator.isZenkaku(" ")); // White space
assertFalse(CharValidator.isZenkaku("azAZ09ヲ゚ !|[]/_"));
assertFalse(CharValidator.isZenkaku("aあ"));
assertFalse(CharValidator.isZenkaku("アZ"));
assertFalse(CharValidator.isZenkaku("0漢字9"));
assertFalse(CharValidator.isZenkaku("\u000F")); // SIN (Control char)
}まとめ
最後に、この記事の内容をまとめます。
要点
- アスキー文字の判定は制御文字の有無で違いがあり注意が必要
- 半角カナ/全角カナ/ひらがなは正規表現で判定できるが、カナ文字をどの範囲にするかは文脈次第
- 半角/全角 文字列の判定は、一文字ごとに判定する方法が有効
文字種の判定処理は、ネットを検索しても色々な方法が紹介されており、この方法ですべての場面に対応できる最強の方法というものがありません。
それは、システムによって微妙に求める要件が違っており、同じカタカナと言ってもどの文字からどの文字までをカタカナと定義するか等、システムごとに定義が変わる可能性があるからです。
半角文字や全角文字という表現も曖昧で、半角文字に「半角カナを含めるのか?」「記号を含めて良いのか?」「制御文字をどう取り扱うか?」などについて、本来はきちんと定義しなければならないのですが、曖昧なまま開発が進行してしまうことが多いようです。
今回紹介した方法も万能ではなく、あなたが開発しているシステムごとに微妙にカスタマイズが必要になると思いますが、ひとつの参考として頂ければ幸いです。
この記事は皆さんからの情報を元に、コードを改善していく予定です。
判定が上手く行かない文字列のパターンや、こうすればもっとシンプルに判定できるなどの意見があれば、是非以下のフィードバックのコメント欄から教えて下さい!