
この記事では、UTF-8 から Shift-JIS に変換する際に文字化けが発生するかを判定するプログラムを紹介しています。
また、文字化けを引き起こす代表的な文字のサンプルもいくつか提示しています。
プログラムで文字コードの変換を行う際、UTF-8 には存在するが Shift-JIS には存在しないという文字の場合、変換時に文字化けが発生します。
環境依存文字やサロゲートペア文字と言われているものが代表的ですね。
以下より、UTF-8からShift-JISに変換できるか判定する方法をJavaのサンプルコードで紹介します。
変換できない文字を検知する基本的な考え方はどの言語でも使える方法なので、Java以外の言語の方でも参考になるかと思います。
文字コードについての基礎や前提知識を学びたい方は、以下の記事も合わせてご覧ください。
-


-
【超初心者向け】文字コードとは何なのか?
この記事では、超初心者向けに文字コードとは何か?について解説しています。 プログラミングに限らず、パソコンやコンピュータを使っていれば誰でも文字化けが発生した経験があると思います。 今回は、プログラミ ...
続きを見る
基本的な考え方
ある文字列を UTF-8 と Shift-JIS にそれぞれ変換します。
「変換前と変換後の文字列が一致する場合は変換可、文字列が一致しない場合は変換不可」と判定できます。
サンプルコードはJavaの例ですが、どの言語でも同じように処理すれば良いと思います。
文字化けする文字の一覧
文字化けを引き起こす代表的な文字をカテゴリーごとに一覧にしました。
これらの文字を使って、文字化けの発生を確認することが出来ます。
| 文字 | カテゴリー |
|---|---|
| 髙(はしご高) | IBM拡張漢字 |
| ①(丸数字) Ⅳ(ローマ数宇) | NEC特殊文字 |
| 🍣🍺(寿司ビール) | 絵文字 |
| 俱(1面14区) 顗(1面94区) | JIS第3水準漢字 |
| 么(2面1区) 鳦(2面94区) | JIS第4水準漢字 |
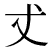 (D840 DC0B) (D840 DC0B) | サロゲートペア文字 |
文字化け判定サンプルコード
このサンプルコードでは、isConvert メソッドで文字コード変換可否の判定をします。
private static boolean isConvert(String text) {
String utf8Text = new String(
text.getBytes(StandardCharsets.UTF_8),
StandardCharsets.UTF_8);
String sjisText = new String(
text.getBytes(Charset.forName("Shift_JIS")),
Charset.forName("Shift_JIS"));
return utf8Text.equals(sjisText);
}更にシンプルな判定方法(Javaのみ)
CharsetEncoder を使うことで、もっと簡単に判定することができます。
import java.nio.charset.Charset;
import java.nio.charset.CharsetEncoder;
private static boolean isConvert(String text) {
CharsetEncoder encoder = Charset.forName("Shift_JIS").newEncoder();
return encoder.canEncode(text);
}サンプルコードの検証
実際に文字化けが発生する文字を使って、上記のサンプルコードを検証します。
文字化けする文字として、以下の例を準備しました。
髙はしご高Ⅳローマ数字\uD840\uDC0Bサロゲートペア文字
※(補足)Javaの内部文字コードはUTF-16 であり、Stringオブジェクトの中身は UTF-16 で保持されています。
public static void main(String args[]) {
String text = "このテキストは文字化けの起きない文字列です。";
System.out.println(isConvert(text) + ": " + text);
text = "髙"; // はしご高 (文字化けする)
System.out.println(isConvert(text) + ": " + text);
text = "Ⅳ"; // ローマ数字 (文字化けする)
System.out.println(isConvert(text) + ": " + text);
text = "\uD840\uDC0B"; // サロゲートペア文字 (文字化けする)
System.out.println(isConvert(text) + ": " + text);
}出力結果
true: このテキストは文字化けの起きない文字列です。
false: 髙
false: Ⅳ
false: ??まとめ
最後に、この記事の内容をまとめます。
要点まとめ
- 文字列を一度 UTF-8 と Shift-JIS のバイナリデータに変換する
- バイナリデータから再度文字列に戻したもの同士が一致するか比較する
- 一致する場合は文字化けしない、一致しない場合は文字化けすると判定する
SJISやEUCなどのいわゆる文字化けが発生してしまう文字には変換しないことが一番の対策ですが、レガシーなシステムとのやり取り等で避けられない場合も往々にしてあるので、文字コード変換の知識は日本でプログラミングをやる上で非常に重要です。
文字コードの問題は一部の特殊な文字でしか顕在化しないので、実装やテスト時の発見が困難なことがあります。
ユーザが入力する氏名や住所などのデータは文字化けが発生しやすいため、そのようなユースケースが想定される場合には、今回の記事のような対策を取る必要があります。
コードで異常を検知したら、該当の文字を削除したり、適切にログやアラートを出すのも解決策の一つになるかと思います。
(※ 業務で氏名などの個人情報をログに出力するのは大抵の場合NGなので気をつけて下さい)
少しでも参考になりましたら幸いです。